If you ask, "What is the main difference between the Public and Enterprise Search Engines?", you might hear the following answer: "The Enterprise Search Engine has connectors. Many connectors. They are needed in order to extract the information from different systems in the enterprise and pass it to the search engine." And it is true, the Enterprise Search Engines are even compared based on the number of connectors they have. More is better!... But is it? Really?
I want to introduce a different approach to the indexing process, which is based not on using connectors to import the data, but instead to make the indexed applications present the data in such a way, that the search engine can access and consume it. Actually, I should say the single connector can access the data and pass it to the search engine. There are advantages to this approach and, as always, there are some disadvantages, so let's start comparing the two architectures and see if the different approach could be of interest to you.
First let's take a look at the standard approach - the search engine has many connectors and uses them to import data for processing and indexing. Here is the picture reflecting the standard approach:
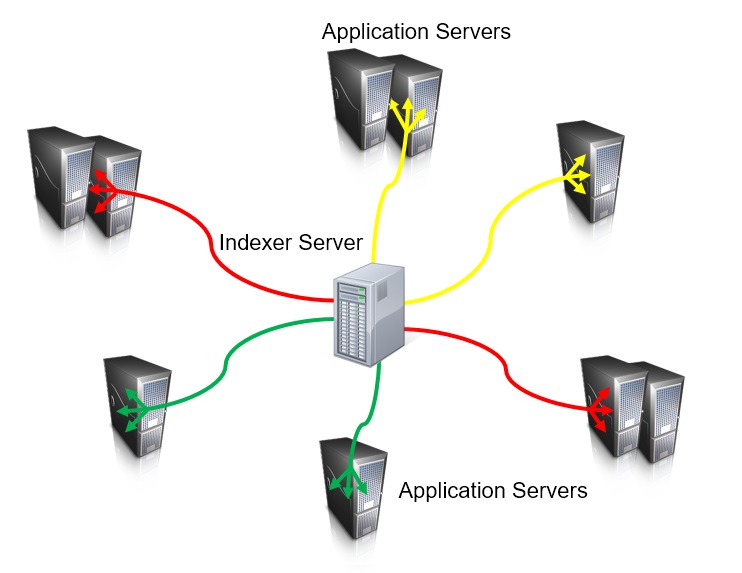
Different connectors are presented on the picture as arrows in different color. You can see that the search engine with the indexing server is in the middle, connected to numerous enterprise applications with connectors and each connector is configured to extract data from each enterprise application using specific configuration. Usually this is not all. Most likely you will need to enrich your data, which requires to add some custom logic to the connector or to the indexed application. Most likely to both. This creates an additional level of complexity, because now part of the connector configuration depends on the indexed application configuration, which I tried to present on a picture by splitting the arrow in three small arrows at the end. The picture above is not very attractive (and not only because I'm a lousy graphic designer! :-) because the indexing server connects directly to enterprise applications and usually it is not a simple configuration.
Because it is usually expensive and involves additional complexity to run multiple search engines, you may end up with a single search engine (unless you have strict security restrictions, for example, to completely separate public and internal content) serving hundreds of different applications (sites) and each of them requires individual connector configuration. Usually after a few years of such "development" the search engine looks like a giant octopus with numerous tentacles stretching to every application in the enterprise, which needs a search service. The applications in the enterprise are usually changing and this calls for constant updates in the configuration of the search engine. This means you will need a system to provide a synchronization between changes in indexed applications and the search engine connectors. And changes mean deployments and testing, and it means people, and this is how every more or less serious enterprise in the end has a "Search Team". The search team is basically a bunch of people who are communicating to enterprise application owners, figuring out what needs to be changed, doing these changes, deploying it to production and verifying that nothing is messed up as a result of such deployment. No exception to this process are the systems, which are crawled remotely with the web spider, but while the web spider still needs a configuration, usually it is much simpler and changes are needed only when the whole site is replaced, added or removed. What a relief you would say, let use more web spiders! But the web spider requires special discussion and, believe me, despite it is usually easier to configure, this is the worst way of doing indexing. We will talk about it later.
Let's take a look how it can be done differently, using an architecture, which does not require multiple connectors. It can be done rather simply if every application or a site in the enterprise will provide some sort of declaration for the search engine containing information on what exactly needs to be indexed. For example, the list of document IDs in the database, or the list of pages on your site. Let's call it an indexing feed. We can make this feed in XML format, somewhat similar to the Google Sitemap. Besides that, the application needs to provide the way to access each indexed document through the web interface. The search engine connector will read the indexing feed and use it for crawling. Ah, crawling again, you would say! But this time it is a different crawling. Actually it is not a crawling at all, it is just reading the documents one by one using entries from the feed provided by the application. The difference is huge.
- First of all there is no 'discovery' of new documents or pages, which means no links from page to page are required to conduct such crawling. The feed contains only documents which should be indexed and nothing else.
- Second, even more important, we can add to each document entry in the indexing feed a timestamp indicating when the document was changed. If the document was already indexed and the timestamp in the feed is matching with the timestamp of previously indexed document, the connector will not index this document again, because the document did not change since the last indexing.
- Third, equally important, is the ability to add metadata to each document using additional XML tags in the feed file. Remember what I said about the connector doing some content enrichment? With regular crawling the enrichment is not possible for document types like PDF. But with the indexing feed it can be done uniformly using additional tags for any type of documents: HTML, Doc, PDF, etc.
The picture of the search engine will look like this:
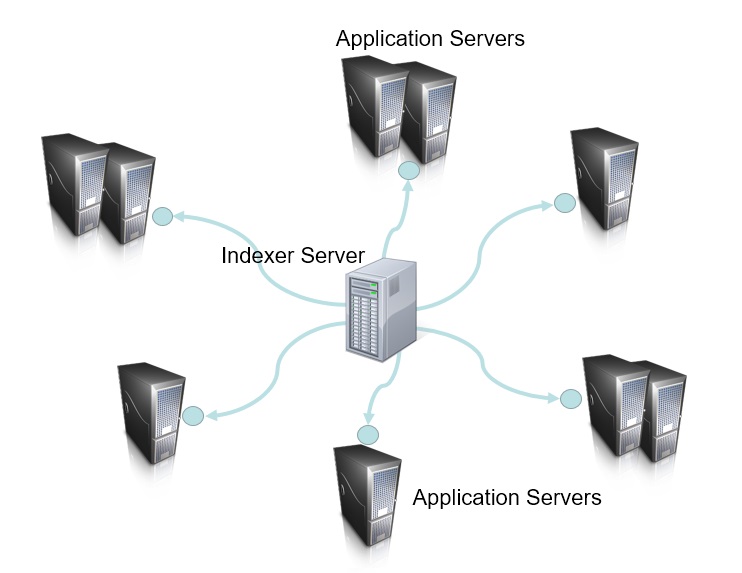
The little circle next to the application server represents the feed provided by the application. We again see the search engine in the middle, but now it is connected to numerous enterprise applications with a single connector and each application in the enterprise is configured to provide data to the search engine in uniformed way. The search engine connector downloads the feed, selects links to new or updated documents using a timestamp and indexes only new or updated entries. If the document is deleted, it is not present in the feed, but still present in the list of documents maintained by the connector and this is how the connector can identify deleted documents. After the indexing of new and updated documents is completed the connector can notify the search engine to remove deleted documents from the index. The feed can have additional tags containing enrichment information for each document, usually it does not take much space.
The disadvantage of this architecture is obvious: Each indexed application needs to provide the indexing feed and make a web interface to download the document. It is a problem, but is it really a big problem? Now the site is usually based on some sort of a Content Management System (CMS). Almost every CMS has an ability to list the documents it has in a REST service using the XML output format. This XML can be used as an indexing feed, which simply has a pagination. For example, if we will take Lotus Notes, IBM added an ability to export the database view in XML format since ver 6.0 (or even earlier). The SharePoint has REST API to list the documents on the site. The Internet websites now support the Google Sitemaps, which with a little customization can be used as an indexing feed. And even if your system has no such ability at all, it usually can be added relatively easy.
If your enterprise application is based on CMS, and the CMS out of the box can produce the indexing feed, the easiest option might be to just customize the connector to recognize such a feed, it is not a difficult customization. If you have applications based on different CMSs, the output format of OOB indexing feeds can be different, which requires customizing the connector to recognize different feed formats. Also, different CMSs might need to use different logic to obtain the feed, so the connector may have a custom class for each CMS it connects to. Most likely you will have just a few different types of indexing feeds with hundreds of applications producing such feeds.
The advantages include:
- The changes in indexed applications can be done by the team maintaining the application and will not affect the search engine connector configuration because the indexing feed format will not change. It means you will have less changes on the search engine end, which means less people in a Search Team.
- The indexing feed can provide additional metadata to enrich the documents.
- There will be no different connectors to maintain, only one connector with a few custom feed format processors. This means the system will become simpler, and simpler means more reliable.
- The indexing can be done much more frequently (in comparison with crawling), because only new and changed documents (delta) are retrieved and indexed. With a little modification this approach can be used even for the Near Real Time (NRT) type of indexing.
Here is one example how the indexing feed can be implemented:

This feed looks pretty much like the Google Sitemap. It lists all documents which need to be indexed. Each document is presented by the "url" tag and the "loc" is a link to the document. Each document has a "lastmod" tag with a timestamp of the last modification. If the timestamp is not provided, the document will be reindexed with each crawling cycle. The first document has only the url and lastmod tags. The second document has additional tags containing information for keywords, subject and a category. The additional tags can be added to provide anything your search application may need, for example ACLs.
Despite that the indexing feed looks a lot like the Google Sitemap, the whole process is different. The Google Sitemap serves only as a help to the web spider to crawl the site. The spider uses each document listed in the Sitemap as a starting point to discover new documents. In our case, however, there is no spidering, because the connector only indexes what was declared in the feed. This is an important distinction, because in the enterprise world it is equally important to index what should be indexed and not to index what should not be indexed. If you will be using readily produced feeds from an existing CMS, the feed format can be different, so the connector should have an ability to recognize different input formats and might need to use different logic to obtain the feed. As I started talking about the web spidering, let me list here other problems you will have with the web spider. As I said above, this is the worst way of doing the indexing and this is why:
- The web spider does not know what should be indexed and what should not. You need to configure it by specifying which URL pattern to index and which not, but this approach is very limited. You can instead add to your site the robots.txt file, but it also uses only URL patterns. You can add to each HTML page on your site the meta tag "robots" and specify on each page to index it or not, but what about the other document types, like PDF or Excel? And if it is not done automatically, is it the easiest way to add this meta tag to every HTML page on the site?
- The web spider relies on consistent URLs to identify each page as a separate document. But what if my site uses session IDs, which are part of the URL and the ID is unique for each indexing session? What if it has URL parameters, which allow presenting just part of the page instead of a whole? What if ... I can continue with these "What ifs" all day, but you got the point. Pretty often, you will end up with a bunch of duplicates in your index, which are different presentations of the same document, but having different URLs. Even if your search engine can deal with it, by identifying duplicates and near-duplicates, it is still huge waste of time and resources to process all this information.
- The web spider needs to extract href links from HTML documents in order to go from one page to another. But what if my collection contains only PDF documents? Or what if I use a beautiful navigation menu made using the JavaScript, which has some sort of complex way of creating such href links? Some advanced web crawlers can discover href links by parsing the JavaScript, but they can do it only if the JavaScript is very simple. Most of the time they cannot. That's how you end up with many "starting points" in your crawler configuration, and this is just a beginning of a mess.
- The web spider requires each page to produce the proper "last modified" date in the header. Without a date you will have each document on your site downloaded with each indexing session. The trick is that the page can be created dynamically for each GET request, so the date will be "now" and we have another problem to deal with.
- And the last one, but certainly not least. How long it will take for a web spider to crawl the site, if the site has, for example, 50,000 pages? And the site owner just complained that the search engine spider overwhelms his site by indexing requests and he wants the search engine to download no more than 1 page per second. Even if the site produces proper "last modified" dates, the header of the page still needs to be requested and loaded to find out if the page needs to be reindexed. Add to 50,000 documents the number of duplicates, multiply it by one second plus time to download the document, plus networking delays and delays from the slow site response and you will get the number. You certainly will not be talking about the NRT indexing!
Regarding the NTR indexing, I have to say that this is a special case and depending on your volumes, you might be better off with the special connector. But it is also possible to implement NTR with the feed approach. The difference is that the indexed application needs to ping the connector as soon as any document is updated and be able to produce a delta feed containing only new, updated or deleted documents with a directive on what to do with each document. The connector should have an ability to listen for this ping, go to the indexed application, download the delta feed and process the documents listed there according to the directives in the feed. At the same time the application still should be able to produce the full feed, which will be crawled on schedule for synchronization.
Another special case is the indexing of very large collection, when one single application contains millions of documents and there is no way to separate them in multiple feeds. I believe you will need a special connector for this as well, but it is a realtively rare case.
Now let's see how the system will look if the connector is external to the search engine, which most likely will be the case, because I never saw any search engine supporting such architecture out of the box.
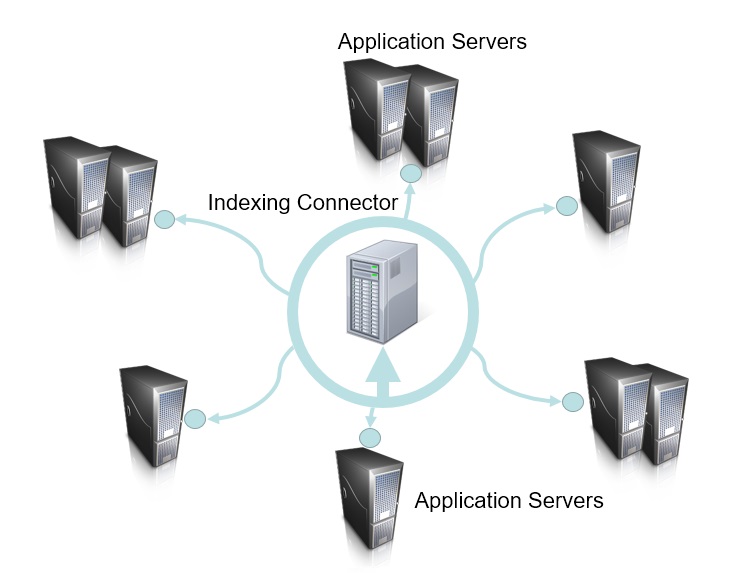
In this case, the indexing connector creates a layer completely separating the search engine from the indexed applications. The search engine has no connectors at all. The connector talks to the applications in your enterprise and sends the information to the search engine in a unified format. Each document of the indexed application is enriched with additional information, which at minimum has the application ID, so that the search engine can produce search results specific to this application if the ID is provided in the search request.
The by-product of such an architecture is a cheaper price of the search engine. Connectors cost money. A lot.
Another important advantage of such an architecture is the simplicity of replacing the search engine with the new one. Newer and better search engines are developed as the technology is progressing and, with advances in artificial intelligence, who knows how smart the search engines may become tomorrow. Imagine, you found a new search engine, which is so much better than the existing one, and now you need to connect the new search engine to all of the applications in the enterprise. If you have the architecture presented on the first picture in this article, it might take literally years to replace the search engine. With the architecture listed here it might take changing only one class in the connector, which talks to the search engine, and on the indexing side you are good to go. Of course, you also need to configure your search schema and to change the front-end search results presentation, but the front-end is usually a simple change. The difference in migration time could be weeks comparing to years and don't forget that you have to pay for both search engines during the migration. The expenses related to the migration can be so significant, that you may just stay with the existing search engine, and the biggest concern is that if your competitors are using newer and more advanced search technology, but you are not, the impact of getting stuck with the old search engine can be huge.
In the end I want to say that this article is not a call to stop using connectors, but an introduction of an alternative architecture, which has its own benefits. What you will choose for your enterprise depends on your environment and your specific requirements, but it is always useful to compare different approaches to find what is best for you.
Vadim Permakoff
Published: May 2017
|